

《科创板日报》2月18日讯(编辑 宋子乔) 2月18日,DeepSeek团队发布一篇论文介绍了新的注意力机制NSA(Natively Sparse Attention,原生稀疏注意力机制)。

NSA专为长文本训练与推理设计,能利用动态分层稀疏策略等方法,通过针对现代硬件的优化设计,显著优化传统AI模型在训练和推理过程中的表现,特别是提升长上下文的推理能力,在保证性能的同时提升了推理速度,并有效降低了预训练成本。
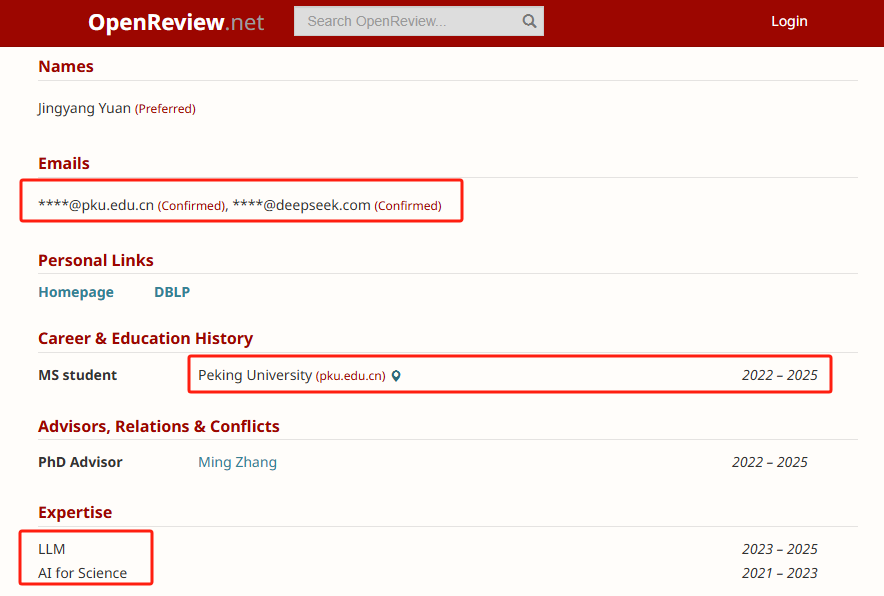
DeepSeek创始人梁文锋现身论文著作者之中,在作者排名中位列倒数第二。

其他研究人员来自DeepSeek、北大和华盛顿大学,其中第一作者Jingyang Yuan(袁景阳)是在DeepSeek实习期间完成的这项研究。
资料显示,袁景阳目前为北京大学硕士研究生。他的研究领域包括大型语言模型(LLM)、人工智能在科学中的应用(AI for Science)。他是DeepSeek-V3技术报告的主要作者之一,还参与了DeepSeek-R1项目,该项目旨在通过强化学习激励大型语言模型的推理能力。
在论文中,DeepSeek团队表示,随着大型语言模型的发展,长上下文建模变得越来越重要,但传统注意力机制的计算复杂度随着序列长度的增加而呈平方级增长,成为制约模型发展的关键瓶颈。
NSA便是为高效处理长上下文任务而生的一种技术路径,其核心创新在于:
1)动态分层稀疏策略:结合粗粒度的Token压缩和细粒度的Token选择,既保证全局上下文感知,又兼顾局部信息的精确性。
2)硬件对齐与端到端训练:通过算术强度平衡的算法设计和硬件优化,显著提升计算速度,同时支持端到端训练,减少预训练计算量。
实验表明,NSA不仅在通用任务和长上下文任务中表现出色,还在链式推理等复杂任务中展现了强大的潜力,且推理速度加快。在通用基准测试、长文本处理以及基于指令的推理任务中,NSA的表现均能达到甚至超越传统全注意力(Full Attention)模型的水平,其以性价比极高的方式,罕见地在训练阶段应用稀疏性,在训推场景中均实现速度的明显提升,特别是在解码阶段实现了高达11.6倍的提升。
通过高效的长序列处理能力,NSA使模型能够直接处理整本书籍、代码仓库或多轮对话(如千轮客服场景),扩展了大语言模型在文档分析、代码生成、复杂推理等领域的应用边界。例如,Gemini 1.5 Pro已展示长上下文潜力,NSA可进一步降低此类模型的训练与推理成本。
本文来自网络转载,不代表阴阳无极 的立场,如若转载,请注明文章转载出处:财联社 , 本站文章链接:https://www.accstt.com/archives/109707.html
的立场,如若转载,请注明文章转载出处:财联社 , 本站文章链接:https://www.accstt.com/archives/109707.html
免责声明:本站致力于为定向人群分享有价值的内容,转载引用仅为传播信息之用,所转载的所有文章、图片、音频、视频文件等资料版权归版权原创作者所有,因非原创文章及图片等内容无法逐一和版权者联系,亦无法核实真实出处,如涉及侵权请联系:QQ:177862291,我们将立即予以删除;



